

I’m working on a freelance contract to write a white paper analyzing the performance of Delphi and Electon executed in an RSS reader benchmark application, a project that builds off my last paper comparing Delphi, Electron, and WPF .NET Framework. The two applications download a few dozen RSS feeds, store them in a PostgreSQL database, and display them in a reading pane.
To compare performance, each application has a built-in timer that measures the total RSS download time from button press (test start) to storing the final article in the database (test end). While this is a reasonable measure of performance, it’s a blunt instrument at best. Assuming the performance of the database is constant since both applications are using the same PostgreSQL server/schema, we can find the framework-processing time by removing milliseconds spent waiting on HTTP GET requests to return data. Although I had success measuring network times for the Delphi application with Fiddler, I wasn’t able to distinguish traffic from the Chromium-based Electron application easily. HTTP Toolkit, itself an Electron app, has a built-in feature to launch and cleanly capture Electron network traffic and works for Delphi using the system proxy or a terminal-specific proxy.
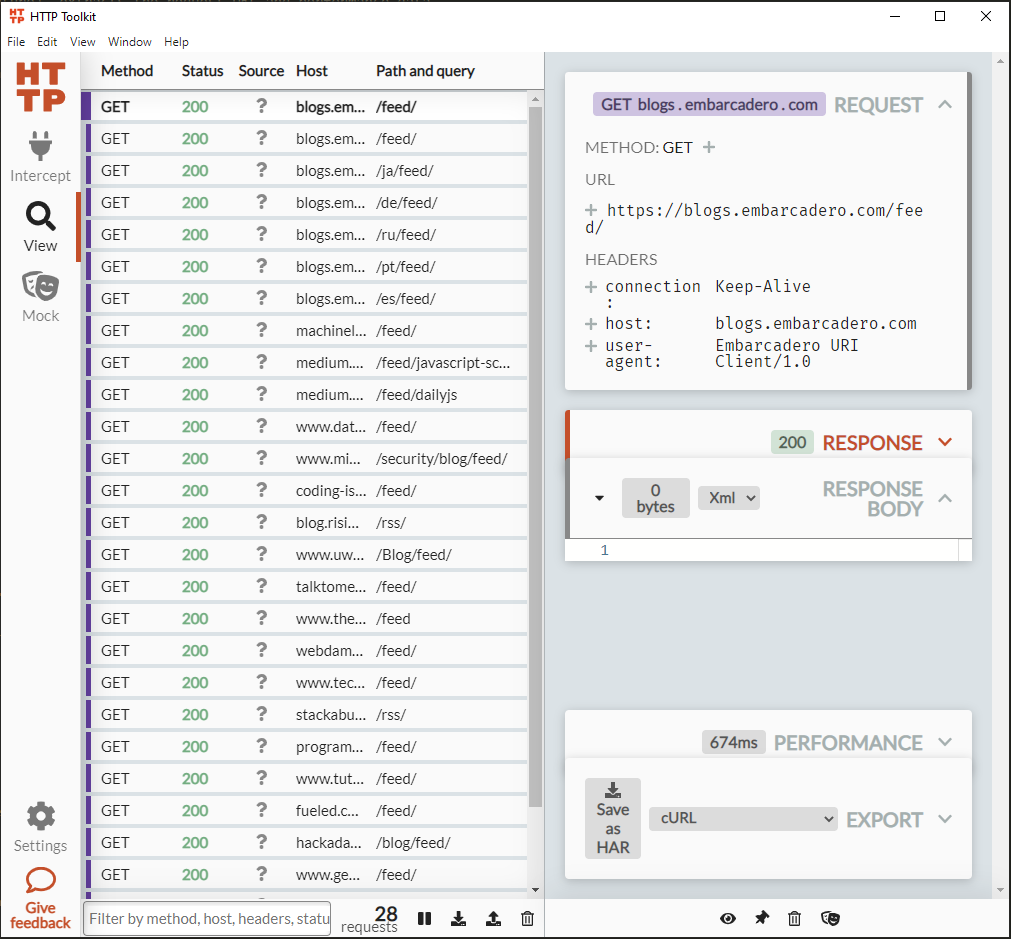
My problem? The Pro version of HTTP Toolkit ($14/mo) gave me performance data in clean, visual ‘cards’ but no easy way to quickly transfer the duration of 25 HTTP GET events to a spreadsheet. After a few rounds of manually selecting 25 events and hand-typing the results into a spreadsheet, this became a “no duh!” automation opportunity. HTTP Toolkit conveniently outputs filtered network events as a .har file – JSON-formatted HTTP Archive File. Now we’re talking!
I’ve been jazzed about Python recently. Part of that is my Temp Buddy work but most of the enthusiasm comes from my purchase and slow read through Automate the Boring Stuff with Python by Al Sweigart.

I love applying programming to my daily or work tasks. The first half of this book is a good primer on Python but the second half is where it gets exciting. Al introduces useful Python libraries and demonstrates how to apply them to common tasks like integrating with office software suites and doing some GUI automation. (He also has half a chapter on JSON parsing but I hadn’t read that yet). One particular library that caught my eye is pyperclip – a set of utilities for interacting with your OS clipboard. His review of regular expressions and file input/output are also excellent. With these in mind, a script to pull network performance data out of the .har files takes shape:
- Validate command line arguments – .har file
- Open the .har file and read all the contents
- Use a regular expression to pick out the HTTP GET request URL and it’s performance data in groups
- Loop over matches, add up the milliseconds, and add the URL and time to a string
- Copy the output string to the clipboard
The Code
- Step one for any python program, imports and starting from a main method.
import pyperclip
import sys
from pathlib import Path
import re
def main ():
# Start program from main method
if __name__ == "__main__":
main()2. File validation is pretty simple – this is a single-use tool for a knowledgable user. If the command-line arguments aren’t long enough, the user didn’t include a .har filepath and validateHARFile can return False, promting main to exit with a message. Otherwise, validate if the given path points to an existing file using the pathlib library Path.is_file function and exit or continue appropriately.
def validHARFile():
if len(sys.argv) < 2:
return False
p = Path(sys.argv[1])
return p.is_file()
def main ():
if not validHARFile():
print ("Invalid .har file! Correct the path and .har filename.")
exit() Next step – opening the file. Python makes this really easy with the open function but it threw some errors in testing, claiming that “s” was a non-Unicode character. Adding the errors="ignore" parameter fixed that issue without negative impacts.
def openHARFile():
try:
harFile = open(sys.argv[1], errors="ignore")
except Exception as e:
print ("Could not open .har file!")
exit()
return harFile
def main ():
...
harFile = openHARFile();3. Here’s where things get spicy. There’s a joke about a programmer with a problem who tries to solve it with regular expressions and ends up with two problems. I really enjoy the challenge of accurate, succinct pattern matching and this format wasn’t too complicated. One network event in the .har file looks like this:
{"id":"Embarcadero","title":"Embarcadero","startedDateTime":"2021-02-22T16:15:50.919-07:00","pageTimings":{}}],"entries":[{"pageref":"Embarcadero","startedDateTime":"2021-02-22T16:15:50.919-07:00","time":674.0097999999998,"request":{"method":"GET","url":"https://blogs.embarcadero.com/feed/","httpVersion":"HTTP/1.1","cookies":[],"headers":[{"name":"connection","value":"Keep-Alive"},{"name":"user-agent","value":"Embarcadero URI Client/1.0"},{"name":"host","value":"blogs.embarcadero.com"}],"queryString":[],"headersSize":-1,"bodySize":0},"response":{"status":200,"statusText":"OK","httpVersion":"HTTP/1.1",
...
"timings":{"blocked":-1,"dns":-1,"connect":-1,"ssl":-1,"send":
8.413699999975506,"wait":306.01720000000205,"receive":359.57890000002226}}],"_tlsErrors":[]}}The parts I want are bolded. The regex pattern captures the start of the GET header, grabs the URL as the first group, uses a non-greedy wildcard to suck up the whole middle of the message, and then captures the timings in three groups at the end of the event. Adding re.VERBOSE in the re.compile function lets us spread the regex over multiple lines for easier reading/organization. Once the pattern is compiled, we run it on the contents of the .har file and exit if no matches were found,or return the list of matches.
def getEventsList(harFile):
harContents = harFile.read()
eventRegEx = re.compile(r'''\"request\":{\"method\":\"GET\",\"url\":\"(.*?)\",\"httpVersion\"
.*? # the middle bits
\"timings\":{.*?,\"send\":(.*?),\"wait\":(.*?),\"receive\":(.*?)}
''', re.VERBOSE)
eventMatches = eventRegEx.findall(harContents)
if (not eventMatches):
print ("No matches")
exit()
else:
return eventMatches
def main ():
...
harFile = openHARFile();
events = getEventsList(harFile)
4. Time for nicely formatted output. I wanted to be able to paste this into a spreadsheet in a column. If the user didn’t specify “quiet” printing via -quiet in the command-line arguments, the output will include the URL and the event duration in milliseconds. If quiet printing is desired, the output will just be event durations.
The regex matches are structured as a list of lists. The main list represents each match of the entire pattern. Sub-lists are created by our pattern groups (regex in parentheses) and can be accessed just like a two-dimensional array. To add each match to a new line in the output string, I used a for-each loop on the main list of patterns and referenced the sub-lists as an index off the iteration variable e. The URL is found in the first index (e[0]) and is added if verbose printing is desired (default). Network event duration is the sum of three times – indeces 1-3.
def formatResults(events):
verbose = True;
if (len(sys.argv) > 2 and sys.argv[2] == "-quiet"):
verbose = False
output = ""
for e in events:
if verbose:
output += e[0] + "\t"
totalTime = float(e[1]) + float(e[2]) + float(e[3])
output += str(totalTime) + "\n"
return output
def main ():
...
events = getEventsList(harFile)
output = formatResults (events)5. Time for my favorite part – copy the results to the clipboard!
def main ():
...
output = formatResults (events)
pyperclip.copy(output)
print ("Matches copied to clipboard")The End Result
This script is simple to run and gives me exactly what I need. It’s already saved me ~20 minutes of manual labor and I’m only halfway through the testing. Not bad for 40 minutes of fun!
PS C:\Users\Adam\Documents> python .\harPerformanceReader.py "C:\Users\Adam\Documents\ubuntu_delphi10.har"
Matches copied to clipboard
Complete Script
# harPerformanceReader
#
# This imports a .har file (network capture), extracts the request URL and performance data
# (total times), and saves them to the system clipboard.
#
# Use
# python ./harPerformanceReader.py .har [-quiet]
#
# Output:
# [URL]\t[Time in milliseconds]\n
#
# Options:
# -quiet Prints times but not URLs
#
# Adam Leone
# 22 Feb 2021
import pyperclip
import sys
from pathlib import Path
import re
def validHARFile():
if len(sys.argv) < 2:
return False
p = Path(sys.argv[1])
return p.is_file()
def openHARFile():
try:
harFile = open(sys.argv[1], errors="ignore")
except Exception as e:
print ("Could not open .har file!")
exit()
return harFile
def getEventsList(harFile):
harContents = harFile.read()
eventRegEx = re.compile(r'''\"request\":{\"method\":\"GET\",\"url\":\"(.*?)\",\"httpVersion\"
.*?
\"timings\":{.*?,\"send\":(.*?),\"wait\":(.*?),\"receive\":(.*?)}
''', re.VERBOSE)
eventMatches = eventRegEx.findall(harContents)
if (not eventMatches):
print ("No matches")
exit()
else:
return eventMatches
def formatResults(events):
verbose = True;
if (len(sys.argv) > 2 and sys.argv[2] == "-quiet"):
verbose = False
output = ""
for e in events:
if verbose:
output += e[0] + "\t"
totalTime = float(e[1]) + float(e[2]) + float(e[3])
output += str(totalTime) + "\n"
return output
def main ():
if not validHARFile():
print ("Invalid .har file! Correct the path and .har filename.")
exit()
harFile = openHARFile();
events = getEventsList(harFile)
output = formatResults (events)
pyperclip.copy(output)
print ("Matches copied to clipboard")
# Start program from main method
if __name__ == "__main__":
main()This program and others I’ve written are available on my GitHub.